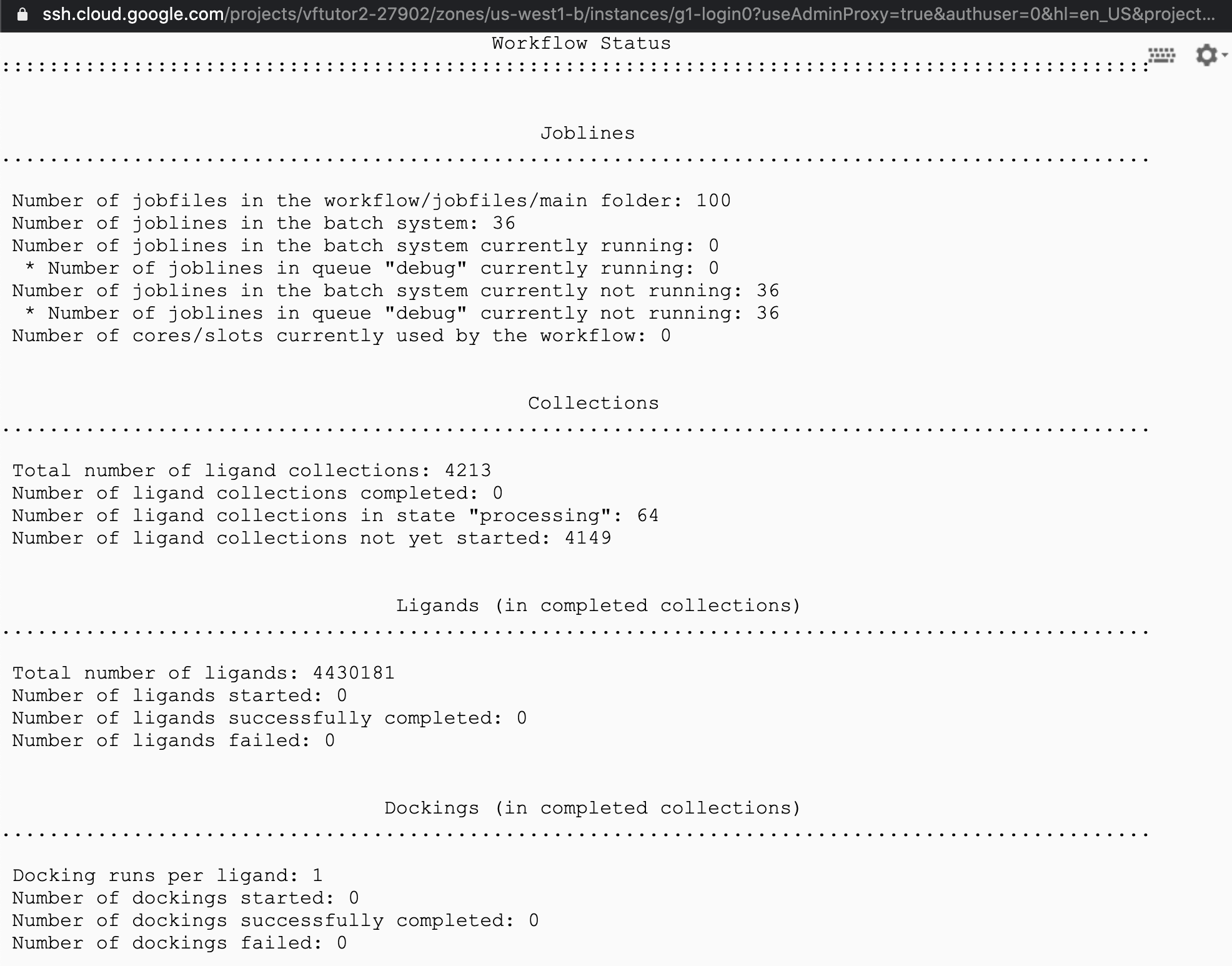
However when I donwload new collections.txt file and run this:
cp collections.txt VFVS_GK/tools/templates/todo.all
mv tranches.sh VFVS_GK/input-files/ligand-library/
and re-start the VF, it starts screening but it does not start running even a single lignad. Attached is my screenshot from monitoring:
Tutorial 2 also does the same thing and I think for the same reason.
It looks like a bug or something to do with updates but not sure.
Did you modify the all.ctrl file and complete all of the other steps listed in the VFVS Tutorial 2? In order to run a set of ligands different from those in Tutorial 1, you will likely need to modify your input folder, all.ctrl file, etc. Without seeing the output/errors from your workflow folder, it is difficult to tell what the problem is.
Hi @audmhugh , thanks for the reply.
After various trials, it started running. I think it took around 5-10 mins before I could observe numbers for “docking started”.
Tutorial 2 also running.
The only current problem I have is about setting the 7 different settings about CPUs. I have no much idea on how to set them correctly. Currently, they are all set as below. But I can see only 8 CPUs as ® running.
I set Slurm in GCP as: n1-standard-8 and max_node_count : 100
I think only 1 node runs and it has 8 CPUs, which might explain the 8 CPUs running currently. I wonder is there a more clear, possible with an example, explanation for these settings to be able to use the maximum CPU capacity?
I am not quite as knowledgeable about those particular settings. I couldn’t figure it out by reading the documentation, so I ended up just trying different numbers until something worked. I also had to change my cluster configuration a bit. My final set up was similar to the one you posted except the last three settings. Those will change based on the tranches you are working with.
The way that your GCP account and cluster is set up will probably limit the number and type of CPUs/nodes that will work at once or per week. Try checking the quota page for your project. I have to change regions/zones occasionally.
steps_per_job=1
# Not (yet) available for LSF and SGE (is always set to 1)
# Should not be changed during runtime, and be the same for all joblines
# Settable via range control files: Yes
cpus_per_step=8
# Sets the slurm cpus-per-task variable (task = step) in SLURM
# In LSF this corresponds to the number of slots per node
# Should not be changed during runtime, and be the same for all joblines
# Not yet available for SGE (always set to 1)
# Settable via range control files: Yes
queues_per_step=8
# Sets the number of queues/processes per step
# Should not be changed during runtime, and be the same for all joblines
# Not yet available for SGE (always set to 1)
# Settable via range control files: Yes
cpus_per_queue=1
# Should be equal or higher than <cpus-per-step/queues-per-step>
# Should not be changed during runtime, and be the same for all joblines
# Not yet available for SGE (always set to 1)
# Settable via range control files: Yes
central_todo_list_splitting_size=10000
# When the folders are initially prepared the first time, the central todo list will be split into pieces of size <central_todo_list_splitting_size>. One task corresponds to one collection.
# Recommended value: < 100000, e.g. 10000
# Possible values: Positive integer
# The smaller the value, the faster the ligand collections can be distributed.
# For many types of clusters it is recommended if the total number of splitted todo lists stays below 10000.
# Settable via range control files: Yes
ligands_todo_per_queue=100000
# Used as a limit of ligands for the to-do lists
# This value should be divisible by the next setting "ligands_todo_per_refilling_step"
# Settable via range control files: Yes
ligands_per_refilling_step=10000
# The to-do files of the queues are filled with <ligands_per_refilling_step> ligands per refill step
# A number roughly equal to the average of number of ligands per collection is recommended
# Settable via range control files: Yes
But in case you missed them, there has been some exchanges on that specific topic in this community, and if you read from some of those links (especially the first one), I think it will help your understanding on how to set those settings :
I think in your case since it looks set for 1 job at a time, I don’t think it makes Slurm scale to multiple nodes, hence you’re only seeing those 8 CPUs on that one node being used.
thanks for the answer. Those settings with the comments below them are not clear enough for me and as I see the same for some other people in this forum too. I am new in this technology. I will try the advices on those links. However, it would be very helpful if there were example scenerios with disucssion to reproduce the case studies of the Nature paper over GCP clusters at least. Those kinds of practical information is quite important imo.
In case, someone has similar issue: My problem turned out to be caused by the default limitatition of CPUs quota of my GCP account. After increasing it, the problem has been solved.