I have been granted 10.000 cores for a total of 500.000CBU time. If im correct this means that I am able to use virtualflow for 50 hours long using 10.000 cores (500000/10000). This means I’m not able to screen 1 billion compounds but less. In the publication Virtualflow author’s mentioned that leveraging 10.000 cores would be able to screen 1 billion compounds in 336 hours, for my 50 hours this means I can roughly screen 140 million compounds.
Now my question is, if I screen 140million compounds with 10000 core what would be the optimal paramaters in the ctrl file for such setup e.g. steps_per_job=1 , cpus_per_step=1 , queues_per_step=1 or cpus_per_queue=1
In additon, how many jobs would be proper to use in ./vf_start_jobline.sh 1 10 templates/template1.slurm.sh submit 1
Welcome back, and congratulations on your obtained computation time
VirtualFlow is quite flexible regarding these settings (to be able to run on any HPC system). The optimal settings will depend on the precise HPC which you are using.
If for example your HPC system always allocates full compute nodes to users/jobs, then I would set cpus_per_step and queues_per_step to the number of cores per compute node. steps_per_job I would for such an HPC system set to something like 10, meaning 10 nodes per job, and cpus_per_queue=1 is always recommended. So if there are 32 cores for instance per node, then one job (with 10 nodes per job) would use a total of 320 cores. Thus if you want to use 10000 in parallel in this case, you would need to submit around 31 jobs.
The number of compounds you can screen with your computation time will depend also on the processor speed. Maybe your CPUs are faster then the ones which were used for the publication
Hi,
I have confusion on these CPU settings after trying 2 different settings regarding this thread. I will share my screenshots while running the, along with my questions which is not clear to me and would be glad if I can get help to clarify them?
I use GCP+ Slurm with maximum 400 CPUs quota and each compute node is set to 8 CPUs per node as this:
Then I set all.ctrl file as suggested above as 1,8,8,1 as below to match number of CPUs per node.
Question 1: The running CPU numbers is not clear between the two case:
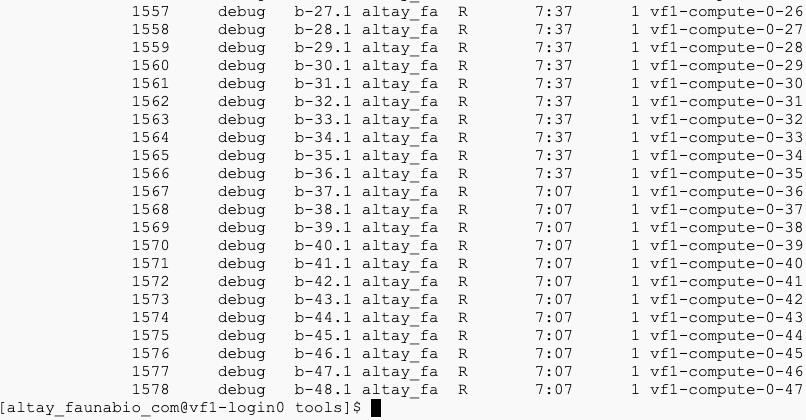
In the current 1,8,8,1 setting run I seem to have normal CPU numbering as this:
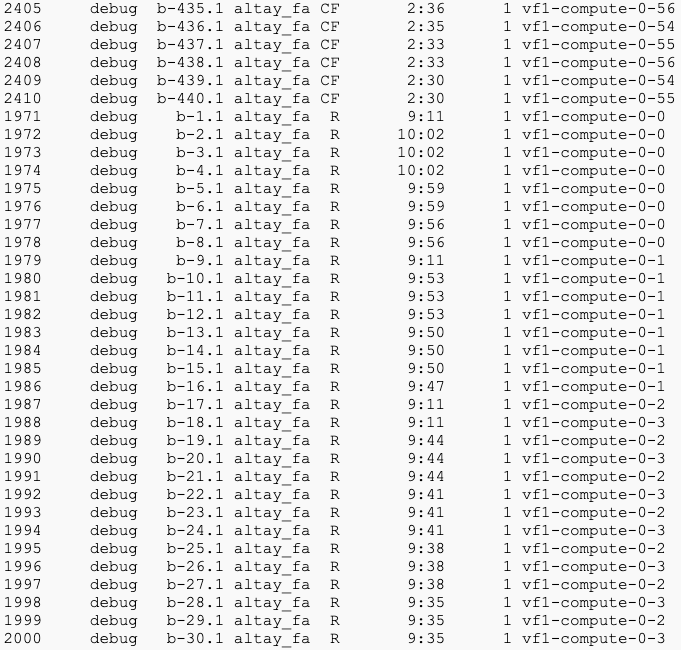
But, if I set CPUs settings as 1,1,1,1 setting run then I see the same CPU numbering 8 times as Running. This made me confused as to whether something is wrong with this setting as it gives the imression to be running the same job 8 times as seen below:
To make sure the setting 1,1,1,1 is clear I paste it below too:
To my experience in the short trials, it feels like 1,1,1,1 setting runs faster but because of this confusion I wanted to clarify it before using it.
Thanks