We are planning to use the COVID-19 shutdown period to explore using VFVS to screen one or more of our targets.
While it seems fairly clear that only very powerful clusters or cloud resources are required to efficiently screen libraries in reasonable timeframes we are being asked specific questions by sysadmins to gain access. In addition we are seeking detailed step-by-step guidance on how to implement the software using local clusters and GCP. I am looking at the tutorials but am anticipating further questions. I am envisioning a local installation and sending most if not all of the calcualtions to the cloud.
Specific questions from sysadmin:
Estimate storage/compute needs required locally and/or on the cloud?
Specifics about when local resources may not be sufficient for timely project progression?
Assuming one active project at a time estimate cloud storage/compute resources per month?
Anticipated cloud-based usage cost per month?
I realize these questions may not have simple answers but any guidance will help me move a proposal forward in addition to getting started with the software.
Thank you for your interest in using VirtualFlow, and welcome to our community
Regarding the questions from your sysadmin:
Storage needs: If you want to screen the entire 1.4 billion compounds, you will need maybe 3-4 TB with a standard screening setup (1 docking scenario). If you screen only a suitable subset of the library, which often makes sense, you can proportionally (linearly) scale the storage needs down.
Compute needs are on average 5-10 seconds per ligand for a stage-1 screening (fastest settings with QuickVina 2). You will need to do some testing with example ligands for your protein and docking setup (e.g. box size). Depending on the number of compounds you want to screen, you can calculate the rough number of needed CPU-hours.
Regarding the required costs in the cloud, this again depends on the number of compounds you want to screen and the precise case (e.g. docking scenarios you are setting up). Please note that you can use pre-emptible virtual machines with VirtualFlow without many problems, which can safe a lot of money. Here is the pricing calculator of the GCP: https://cloud.google.com/products/calculator
Thanks for this answer. Could you share further details on how you set up the computing on GCP as published in your recent paper?
Specifically -
Which job manager did you use?
How many instances? Did you have to use a main instance that controlled other instances?
What size CPUs/memory did you use?
What type of CPU? (google offers a broad range - memory vs compute optimized CPU, TPUs and GPUS)
How far downward does your linear scaling work? Using the numbers you provided, if one wanted to screen fewer compounds - say 200K - it should only take about 5 hours on 100 CPUs. Does this sound right?
I recently deployed VirtualFlow on GCP and used Slurm as a scheduler, and for File Storage I have tried both Elastifile and Filestore.
You can find instructions on how to deploy Elastifile here (caveat: it uses Terraform 0.11, and did not work for me with 0.12 so I had to downgrade Terraform)
You can find instructions on how to create a Filestore instance here (fairly straight forward, once your volume is created you’ll just point to it in your cluster nodes deployment)
You can find instruction to deploy Slurm on GCP here and as an example, here is the Terraform variables file that I used for my deployment (again it was for a test so I’m using standard VMs)
Regarding the type of CPU it depends how quickly you want your jobs executed and the type of jobs, some variable are tunable via the Slurm configuration. It also depends your budget. You can leave aside GPU and TPU and plan to use CPUs from standard instances like N1 or N2. As mentioned in this thread I’d recommend using preemptible VMs to reduce the cost
Hopefully this helps get you started on Google Cloud.
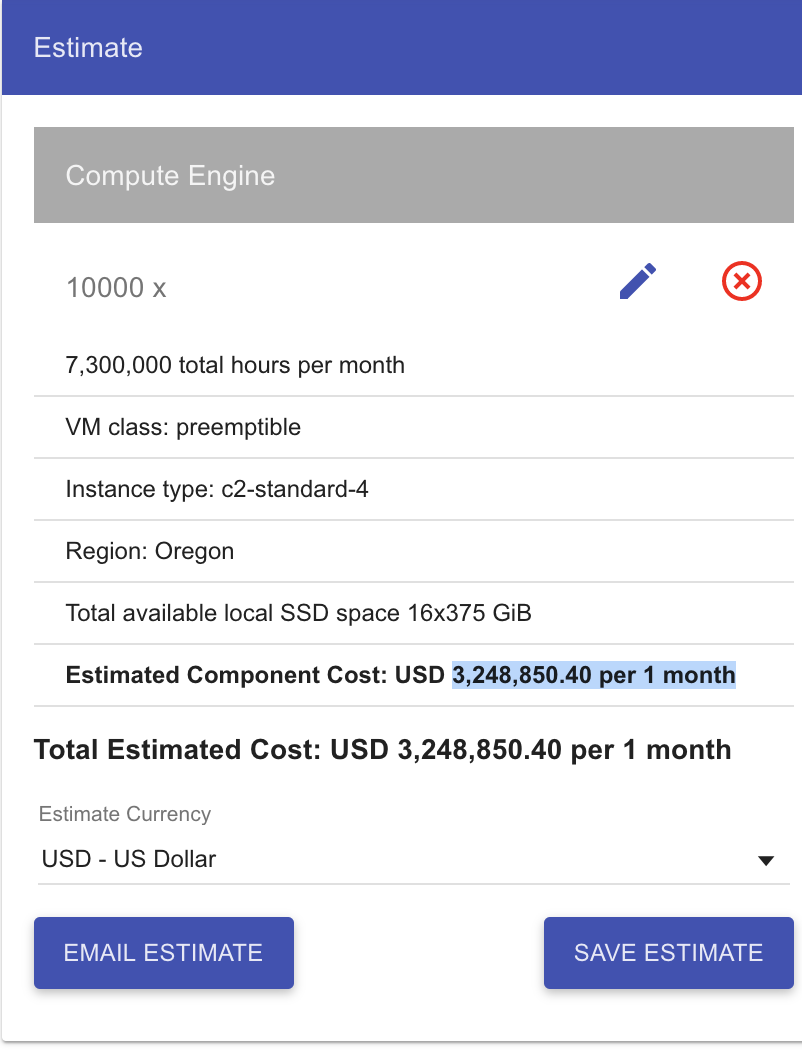
I tried this calculator, but without a more detailed guidance, it seems more of a guess of how to select the right setting for VirtualFlow, for at least the case we read in the Nature paper .
For example I tried to calculated this for 10000 CPUs, which estimates 3,248,850.40 per 1 month!
Regarding the calculator, it seems that if gives only the price per months. With sufficiently many CPUs you need usually much less time, but it depends on the precise settings you are using.
Hi @gal, I have not tried the Slurm install I did back in April in the last 6 months, so I’d say you might be better off trying the link you shared as it seems more recent. Sometimes due to changes in Terraform versions, changes in some pieces of the code, you might bump into issues due to that.
Ultimately, once you have a stable Slurm install and a file system solution up and running you should be able to install VirtualFlow on top of if without much trouble.